Serverless Computing With Apache Ignite and Azure Functions

Apache Ignite Committer and PMC Member
This tutorial walks you through the process of creating an application that makes use of serverless and in-memory computing. Serverless computing is a new way of cloud-native application development and hosting, while in-memory computing is a software and data-processing technique that stores data sets in memory across a cluster of interconnected nodes. With serverless computing, you can focus on application logic creation, letting a cloud vendor provide, manage, and scale the needed infrastructure. In contrast, with in-memory computing, you can process your data 100-1000x faster than with disk-based databases.
What You Will Develop
You will build a serverless Azure Function that uses Apache Ignite in-memory computing platform as a database and compute engine. The function will respond to several HTTP requests and use Ignite SQL with compute APIs to perform requested computations.
An Apache Ignite cluster will be deployed in and managed by Azure Kubernetes Service (AKS). Your Azure Function will be interacting with the cluster using the Java thin client and a REST endpoint open on the Ignite end.
By the end of the tutorial, you are going to finish this sample GitHub project by adding a complete implementation of the Azure Function. Also, the project includes configuration files that will help to expedite Ignite deployment and the function deployment in Azure.
What You Need
-
A Microsoft Azure account with an active subscription.
-
Apache Ignite 2.8 or later version.
-
The Java Developer Kit, version 8.
-
Apache Maven 3.0 or later version.
-
Favourite IDE such as IntelliJ IDEA or Eclipse.
Deploy Kubernetes Cluster With AKS
Kubernetes will manage the Ignite cluster. In this section you will deploy a 2-node Kubernetes cluster with AKS.
-
Go to https://portal.azure.com/, locate
Kubernetes Servicein the marketplace and start defining the Kubernetes cluster’s basic parameters. -
Create a
Resource groupnamedignite-azure-function-demo, set the cluster name toIgniteClusterandNode countto2. Change other settings only if you are sure that’s needed.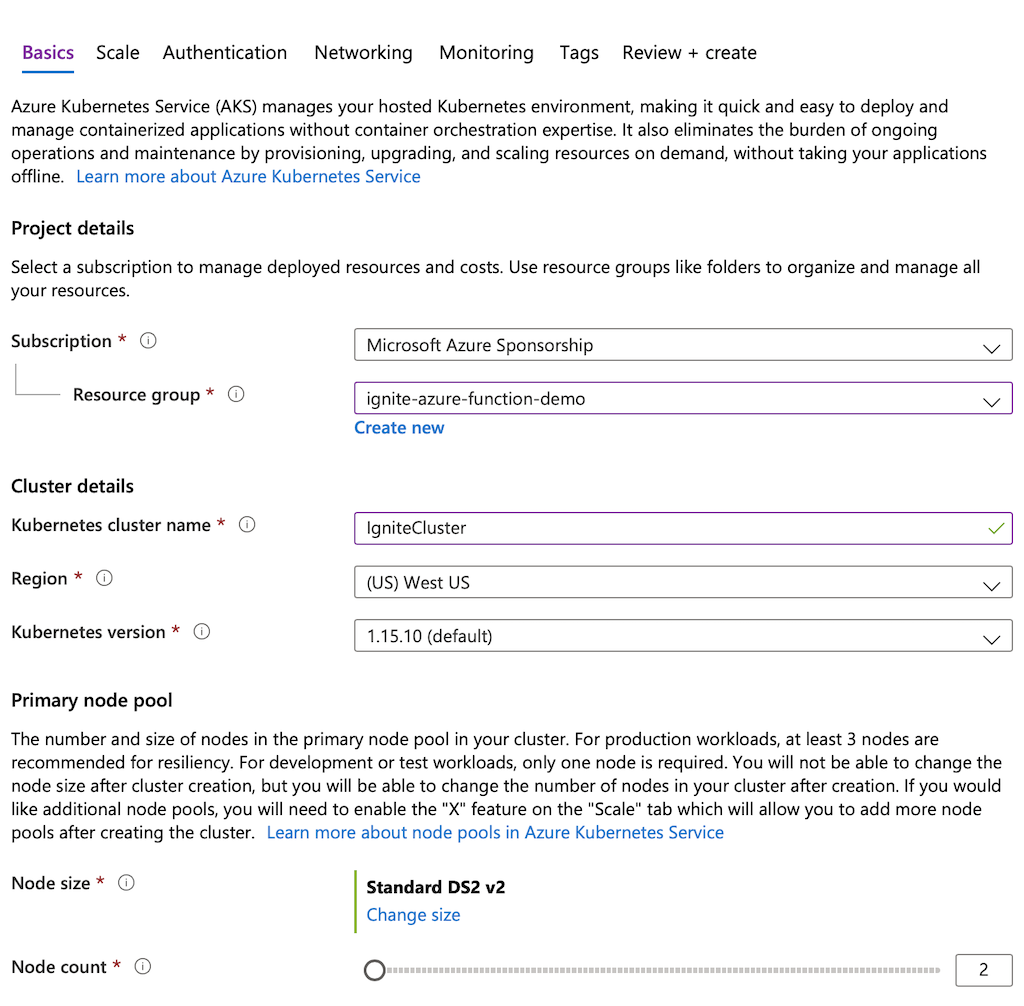
-
Jump to the
Authenticationsettings screen. Select yourService principaland ensure RBAC is enabled.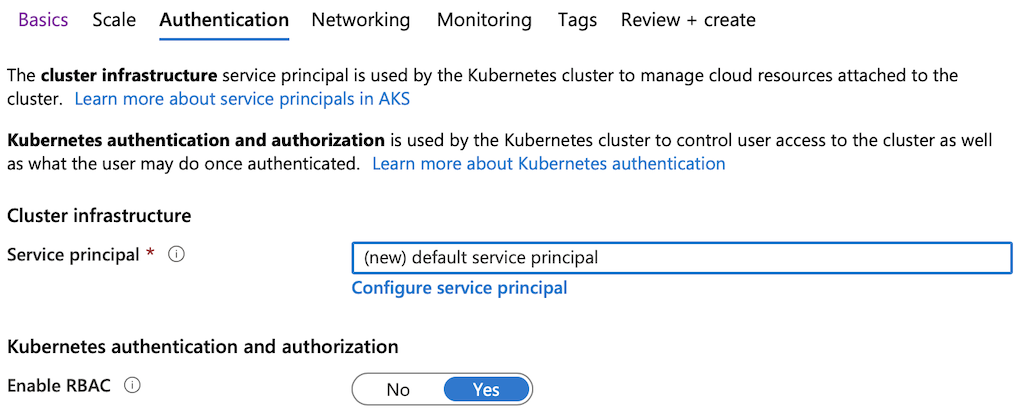
-
Go to the
Networkingtab and setDNS name prefixtoIgniteCluster-dns. Leave other parameters unchanged unless it’s required.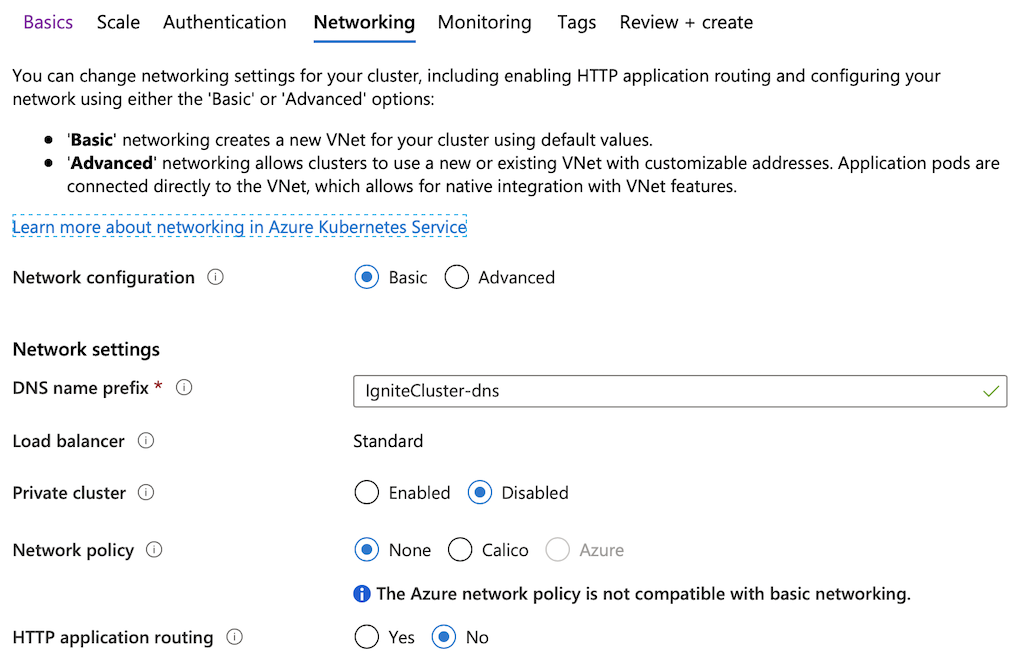
-
Enable monitoring feature of Azure by proceeding to the
Monitoringscreen.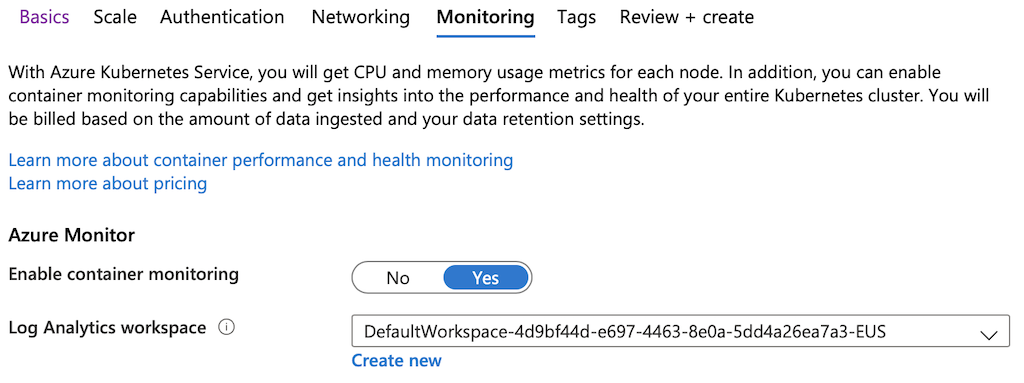
-
Validate the configuration parameters on the
Review+createscreen and bootstrap Kubernetes by clicking on theCreatebutton. -
Once Azure finishes provisioning of the requested resources, open a command-line terminal and use Azure CLI tool to import the resource group credentials:
az aks get-credentials --resource-group ignite-azure-function-demo --name IgniteCluster -
Finally, use kubctl to confirm that the Kubernetes cluster is accessible from your environment:
kubectl get nodesThe command should produce an output similar to this:
NAME STATUS ROLES AGE VERSION aks-agentpool-41263829-vmss000000 Ready agent 13m v1.15.10 aks-agentpool-41263829-vmss000001 Ready agent 13m v1.15.10
Deploy Apache Ignite Cluster in Kubernetes
In this section you will learn to create a 2-node Ignite cluster within the Kubernetes environment and make it accessible through an instance of the Kubernetes Service.
-
Start with downloading Azure Functions With Apache Ignite GitHub project that comes with predefined configuration files and source code templates, which you will be using later while developing an Azure Function. The project includes several Kubernetes-specific configuration files located in the
sample_project_root/cfgfolder. Open that folder and create a unique namespace for the Ignite cluster:cd {sample_project_root}/cfg kubectl create namespace ignite-azure-function-demo -
Create a service account:
kubectl create sa ignite-azure-function-demo -n ignite-azure-function-demo -
Create a cluster role and the role binding:
kubectl create -f ignite-cluster-role.yaml -
Proceed with the Ignite Service creation that will serve as a Kubernetes LoadBalancer letting Azure Function’s logic interact with Ignite through open network ports and interfaces:
kubectl create -f ignite-service.yaml -
Deploy the 2-nodes Ignite cluster with the settings from
ignite-deployment.yamlfile:kubectl create -f ignite-deployment.yaml -
Confirm that the cluster is up-and-running:
kubectl get pods -n ignite-azure-function-demoThe command should produce an output similar to the one below:
NAME READY STATUS RESTARTS AGE ignite-cluster-dfb6489c5-4wv57 1/1 Running 0 28s ignite-cluster-dfb6489c5-xpxdm 1/1 Running 0 28s -
Find the external IP address that was given to the Ignite Service by Kubernetes. You can obtain it by taking the value of
EXTERNAL-IPreported by the following command:kubectl get svc ignite-service --namespace=ignite-azure-function-demo -
Check that Ignite is reachable outside of Kubernetes by opening the URL
http://YOUR-EXTERNAL-IP:8080/ignite?cmd=versionin your browser or by usingcurl:curl http://YOUR-EXTERNAL-IP:8080/ignite?cmd=versionThe response should be as follows, meaning that Ignite REST endpoints are open and ready to process the API requests:
{"successStatus":0,"sessionToken":null,"error":null,"response":"2.8.0"}
Load Data to Apache Ignite With JDBC Driver
Now that the cluster running and reachable, your next step is to load it with sample data. The sample project that you downloaded in the
previous section includes the sample_project_root/cfg/ignite_world_db.sql file that creates a database of countries and cities. The
database is simple and perfectly suited for experiments with various Ignite capabilities.
Check ignite_world_db.sql for the following key settings:
-
Records of
Citytable are co-located withCountrytable by setting theaffinityKey=CountryCodeparameter in theCREATE TABLE Citystatement. With affinity co-location in place, your Azure Function will be able to run high-performance SQL with JOINs and schedule compute tasks that iterate through related data of a particular cluster node. -
CREATE TABLEstatements of all the tables setCACHE_NAMEandvalue_typeparameters to specific values. You need this to access the records with Ignite cache and key-value APIs.
Follow the steps below to load sample data using the Apache Ignite JDBC driver:
-
To get the driver, download the Apache Ignite binary distribution of 2.8 or later version and unpackage it in a local directory. Go to the
binfolder of that local directory:cd {ignite-binary-release}/bin/ -
Open a JDBC connection to your cluster by using the SQLLine tool shipped with Ignite (use
sqlline.batfor Windows):./sqlline.sh -u jdbc:ignite:thin://YOUR-EXTERNAL-IP/ -
Once the connection is established, load the database of countries and cities:
!run {sample_project_root}/cfg/ignite_world_db.sql -
Run the
!tablecommand to confirm the following three tables are created in Ignite:+--------------------------------+--------------------------------+------------+ | TABLE_CAT | TABLE_SCHEM | | +--------------------------------+--------------------------------+------------+ | IGNITE | PUBLIC | CITY | | IGNITE | PUBLIC | COUNTRY | | IGNITE | PUBLIC | COUNTRYLAN | -
Close the JDBC connection by executing the
!exitcommand.
With this step finished, you are ready to develop an Azure Function that will serve a couple of requests and delegate their processing to the Ignite cluster managed by Azure Kubernetes Service.
Develop Azure Function
Now you will develop an Azure Function that serves two types of HTTP requests. The function will send Ignite SQL queries via a thin client connection to process the first request. With the second request, you will learn how to use Ignite REST APIs to trigger the execution of compute tasks.
Open the sample project in your favorite IDE, such as IntelliJ IDEA or Eclipse, and locate the
org.gridgain.demo.azurefunction.functions.AzurePopulationFunction class, which is a source code template with a single method
annotated with @FunctionName("population"). Once you finish this section, the method will embody the Azure Function’s
logic that processes HTTP requests.
Establish Thin Client Connection
-
Add the following fields to the
AzurePopulationFunctionclass:private static final Object monitor = new Object(); private static volatile IgniteClient thinClient; //Set the address to the EXTERNAL-IP of the Ignite Kubernetes Service private static final String CLUSTER_IP = "YOUR-EXTERNAL-IP"; -
Initialize the
CLUSTER_IPfield with the external IP address of your Ignite Kubernetes Service. -
Introduce the method that will be opening a single thin client connection. This instance will be reused for multiple invocations of the Azure Function:
private IgniteClient getThinClientConnection() { if (thinClient == null) { synchronized (monitor) { ClientConfiguration cfg = new ClientConfiguration().setAddresses(CLUSTER_IP + ":10800"); thinClient = Ignition.startClient(cfg); } } return thinClient; }
Retrieve Most Populated Cities
The function will process HTTP requests asking to return all the cities with population greater than a given number. Ignite SQL engine handles such queries by filtering out records that do not meet the search criteria as well as by joining, grouping, and ordering of the distributed data.
Add an implementation of the method to the AzurePopulationFunction class, which queries Ignite with SQL via the thin client
connection:
private HttpResponseMessage getCitiesPopulationGreaterThan(int population, HttpRequestMessage<Optional<String>> request) {
SqlFieldsQuery sqlQuery = new SqlFieldsQuery("SELECT city.name, city.population, country.name " +
"FROM city JOIN country ON city.countrycode = country.code WHERE city.population >= ? " +
"GROUP BY country.name, city.name, city.population ORDER BY city.population DESC, city.name")
.setArgs(population);
List<List<?>> result = getThinClientConnection().query(sqlQuery).getAll();
HttpResponseMessage.Builder responseBuilder = request.createResponseBuilder(HttpStatus.OK);
responseBuilder.header("Content-Type", "text/html");
StringBuilder response = new StringBuilder("<html><body><table>");
for (List<?> row: result) {
response.append("<tr>");
for (Object column: row)
response.append("<td>").append(column).append("</td>");
response.append("</tr>");
}
response.append("</table></body></html>");
return responseBuilder.body(response.toString()).build();
}Once Ignite responds, the function will wrap result set’s records into an HTML format.
Calculate Average Population
Add another method to the AzurePopulationFunction class, which calculates the average population
across all the cities of a given country:
private HttpResponseMessage getAvgPopulationInCountry(String countryCode, HttpRequestMessage<Optional<String>> request) {
CloseableHttpClient httpClient = HttpClients.createDefault();
HttpGet httpGet = new HttpGet("http://" + CLUSTER_IP +
":8080/ignite?cmd=exe&name=org.gridgain.demo.azurefunction.compute.AvgCalculationTask&p1=" + countryCode);
CloseableHttpResponse response = null;
try {
response = httpClient.execute(httpGet);
HttpEntity entity1 = response.getEntity();
StringWriter writer = new StringWriter();
IOUtils.copy(entity1.getContent(), writer, StandardCharsets.US_ASCII);
return request.createResponseBuilder(HttpStatus.OK).body(writer.toString()).build();
} catch (IOException e) {
e.printStackTrace();
return request.createResponseBuilder(HttpStatus.BAD_GATEWAY).body(
"Failed to execute the request: " + e.getMessage()).build();
}
finally {
try {
if (response != null)
response.close();
}
catch (IOException e) {
e.printStackTrace();
}
}
}The method triggers the execution of org.gridgain.demo.azurefunction.compute.AvgCalculationTask compute task with the help
of Ignite’s execute command supported by its REST API.
Ignite Compute APIs
are the right fit for such types of requests as long as they allow to run data-intensive or compute-intensive Java logic on
specific cluster nodes with no or minimal data movement between the cluster and applications.
If you check the implementation of AvgCalculationTask located in the sample project, you will see that once triggered,
the task will determine a cluster node that stores all the cities of the given country and will request only that node
to traverse through the local data calculating the population average.
This technique is known as co-located data processing.
Handle User Requests
Replace the AzurePopulationFunction.run(…) method implementation with the following logic:
@FunctionName("population")
public HttpResponseMessage run(
@HttpTrigger(name = "req", methods = {HttpMethod.GET, HttpMethod.POST}, authLevel = AuthorizationLevel.ANONYMOUS) HttpRequestMessage<Optional<String>> request,
final ExecutionContext context) {
context.getLogger().info("Java HTTP trigger processed a request.");
// Determining a type of request
String query = request.getQueryParameters().get("popGreaterThan");
String paramValue = request.getBody().orElse(query);
if (paramValue != null)
//Getting all the cities with population greater or equal to the specified one.
return getCitiesPopulationGreaterThan(Integer.valueOf(paramValue), request);
query = request.getQueryParameters().get("avgInCountry");
paramValue = request.getBody().orElse(query);
if (paramValue != null)
//Calculating average population in the country.
return getAvgPopulationInCountry(paramValue, request);
return request.createResponseBuilder(HttpStatus.BAD_REQUEST).body(
"Not enough parameters are passed to complete your request").build();
}Once deployed, the Azure Function will intercept queries at /api/population endpoint, and depending on the query,
the parameters will call one of previously added class methods:
-
If the
popGreaterThanparameter is present in the query, then the function will execute theAzurePopulationFunction.getCitiesPopulationGreaterThan(…)method. -
Otherwise, the function expects to see the
avgInCountryparameter to execute the logic of theAzurePopulationFunction.getAvgPopulationInCountry(…)method.
That’s it. You’ve developed the Azure Function that works with Ignite as a in-memory database and compute engine. The next step is to test the implementation locally and deploy it to Azure.
Complete Function Implementation
Below is a complete implementation of the AzurePopulationFunction class that you might want to compare with your version. Only
the value of the CLUSTER_IP field should be different on your side.
package org.gridgain.demo.azurefunction.functions;
import java.io.IOException;
import java.io.StringWriter;
import java.nio.charset.StandardCharsets;
import java.util.*;
import com.microsoft.azure.functions.annotation.*;
import com.microsoft.azure.functions.*;
import org.apache.commons.io.IOUtils;
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.ignite.Ignition;
import org.apache.ignite.cache.query.SqlFieldsQuery;
import org.apache.ignite.client.IgniteClient;
import org.apache.ignite.configuration.ClientConfiguration;
/**
* Azure Functions with HTTP Trigger.
*/
public class AzurePopulationFunction {
//tag::class_fields[]
private static final Object monitor = new Object();
private static volatile IgniteClient thinClient;
//Set the address to the EXTERNAL-IP of the Ignite Kubernetes Service
private static final String CLUSTER_IP = "YOUR-EXTERNAL-IP";
//end::class_fields[]
/**
* This function listens at endpoint "/api/population" and processes two types of requests:
*
*/
//tag::azure_function_impl[]
@FunctionName("population")
public HttpResponseMessage run(
@HttpTrigger(name = "req", methods = {HttpMethod.GET, HttpMethod.POST}, authLevel = AuthorizationLevel.ANONYMOUS) HttpRequestMessage<Optional<String>> request,
final ExecutionContext context) {
context.getLogger().info("Java HTTP trigger processed a request.");
// Determining a type of request
String query = request.getQueryParameters().get("popGreaterThan");
String paramValue = request.getBody().orElse(query);
if (paramValue != null)
//Getting all the cities with population greater or equal to the specified one.
return getCitiesPopulationGreaterThan(Integer.valueOf(paramValue), request);
query = request.getQueryParameters().get("avgInCountry");
paramValue = request.getBody().orElse(query);
if (paramValue != null)
//Calculating average population in the country.
return getAvgPopulationInCountry(paramValue, request);
return request.createResponseBuilder(HttpStatus.BAD_REQUEST).body(
"Not enough parameters are passed to complete your request").build();
}
//end::azure_function_impl[]
//tag::cities_population_greater_than_method[]
private HttpResponseMessage getCitiesPopulationGreaterThan(int population, HttpRequestMessage<Optional<String>> request) {
SqlFieldsQuery sqlQuery = new SqlFieldsQuery("SELECT city.name, city.population, country.name " +
"FROM city JOIN country ON city.countrycode = country.code WHERE city.population >= ? " +
"GROUP BY country.name, city.name, city.population ORDER BY city.population DESC, city.name")
.setArgs(population);
List<List<?>> result = getThinClientConnection().query(sqlQuery).getAll();
HttpResponseMessage.Builder responseBuilder = request.createResponseBuilder(HttpStatus.OK);
responseBuilder.header("Content-Type", "text/html");
StringBuilder response = new StringBuilder("<html><body><table>");
for (List<?> row: result) {
response.append("<tr>");
for (Object column: row)
response.append("<td>").append(column).append("</td>");
response.append("</tr>");
}
response.append("</table></body></html>");
return responseBuilder.body(response.toString()).build();
}
//end::cities_population_greater_than_method[]
//tag::country_avg_population_method[]
private HttpResponseMessage getAvgPopulationInCountry(String countryCode, HttpRequestMessage<Optional<String>> request) {
CloseableHttpClient httpClient = HttpClients.createDefault();
HttpGet httpGet = new HttpGet("http://" + CLUSTER_IP +
":8080/ignite?cmd=exe&name=org.gridgain.demo.azurefunction.compute.AvgCalculationTask&p1=" + countryCode);
CloseableHttpResponse response = null;
try {
response = httpClient.execute(httpGet);
HttpEntity entity1 = response.getEntity();
StringWriter writer = new StringWriter();
IOUtils.copy(entity1.getContent(), writer, StandardCharsets.US_ASCII);
return request.createResponseBuilder(HttpStatus.OK).body(writer.toString()).build();
} catch (IOException e) {
e.printStackTrace();
return request.createResponseBuilder(HttpStatus.BAD_GATEWAY).body(
"Failed to execute the request: " + e.getMessage()).build();
}
finally {
try {
if (response != null)
response.close();
}
catch (IOException e) {
e.printStackTrace();
}
}
}
//end::country_avg_population_method[]
//tag::thin_client_connection_method[]
private IgniteClient getThinClientConnection() {
if (thinClient == null) {
synchronized (monitor) {
ClientConfiguration cfg = new ClientConfiguration().setAddresses(CLUSTER_IP + ":10800");
thinClient = Ignition.startClient(cfg);
}
}
return thinClient;
}
//end::thin_client_connection_method[]
}Set Unique Azure Function Name
To avoid possible naming conflicts, open the {sample_project_root}/pom.xml file and adjust the value of the <functionAppName>
parameter to ignite-azure-function-demo-{your-name}-{some-random-number} format. Otherwise, you may fail to deploy your function in case
someone else has it running in Azure with the default name set in pom.xml.
Test Azure Function Locally
Before deploying the function to Azure, you can confirm that it works as expected in your local development environment. To do that:
-
Open the terminal and go to the root of the sample project:
cd {sample_project_root} -
Build the package with Maven:
mvn clean package -DskipTests -
Deploy the function locally:
mvn azure-functions:run -
Look for a line similar to
population: [GET,POST] http://localhost:7071/api/populationin the output of the previous command. -
Assuming that the function listens for incoming requests on port number 7071, open the following page in your browser window http://localhost:7071/api/population?popGreaterThan=9000000. The function will return all the cities with a population equal or more than 9 million people:

-
Next, see what is the average population of the cities in the United States by opening this URL - http://localhost:7071/api/population?avgInCountry=USA. Look for the following info in the response:
Calculation Result [avgPopulation=286955, citiesCount=274, partition=354, nodeId=8c8c51aa-02fc-42fc-a488-9447eecb674b, nodeAddresses=[10.244.0.11, 127.0.0.1]]In addition to the average population (
avgPopulation) and number of cities in the country (citiesCount), the response includes thepartitionnumber that keeps all the cities of the USA and some details (nodeIdandnodeAddresses) about the cluster node that stores the primary copy of the partition.
You can experiment with the function by passing different values to /api/population?popGreaterThan=? and /api/population?avgInCountry=? URLs.
The latter requires to pass a country code in the
ISO Alpha-3 format (aka. three letter code).
Deploy Function to Azure
Finally, you can now deploy the function to Azure. To do that:
-
Stay in the root directory of the sample project and log in with Azure from the terminal:
az login -
Build the package (skip this test if you completed the previous step of this tutorial by testing the function locally):
mvn clean package -DskipTests -
Start deploying the function by executing the following Maven task defined in
pom.xmlof the sample project:mvn azure-functions:deployWhen the function is deployed, Azure will assign a public address to the function that should look like as follows (locate a similar line in the Maven output):
[INFO] Successfully deployed the function app at https://ignite-azure-function-demo-20200417133129560.azurewebsites.net. -
Open
https://YOUR-AZURE-FUNCTION-NAME.azurewebsites.net/api/population?popGreaterThan=9000000in your browser to see the function working. Play with the function by passing different values topopGreaterThanandavgInCountryrequest parameters the way it was done in the previous section when you tested everything locally.
Congratulations! You’ve completed the tutorial and learned how to use serverless and in-memory computing together.
Learn More
-
Configure Ignite Persistence for your Azure Kubernetes Service deployment to keep full copy of records on disk and to enable fast restarts of the Ignite cluster.
-
Monitor and manage the Ignite cluster with GridGain WebConsole
© 2026 GridGain Systems, Inc. All Rights Reserved. Privacy Policy | Legal Notices. GridGain® is a registered trademark of GridGain Systems, Inc.
Apache, Apache Ignite, the Apache feather and the Apache Ignite logo are either registered trademarks or trademarks of The Apache Software Foundation.