GridGain Blog

Publisher's Note: the article describes a custom data loading technique that worked best for a specific user scenario. It's neither a best practice nor a generic approach for data loading in Ignite. Explore standard loading techniques first, such as IgniteDataStreamer or CacheStore.loadCache, which can also be optimized for loading large data sets.
Now, in-memory cache technology is becoming…

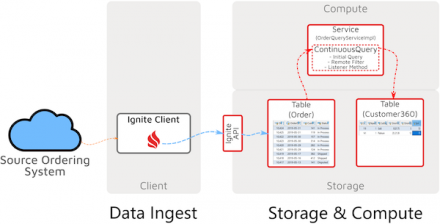
Using the initial-query, listener, and remote-filter features of Ignite continuous queries to detect, filter, process, and dispatch real-time events
(Note that this is Part 3 of a three-part series on Event Stream Processing. Here are the links for Part 1 and Part 2.)
Real-time handling of streams of business events is a critical part of modern information-management systems, including online…
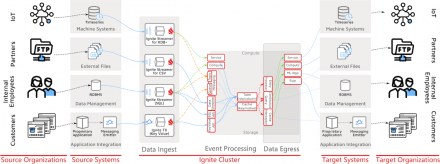
Building an Event Stream Processing Solution With Apache Ignite
(Note that this is Part 2 of a three-part series on Event Stream Processing. Here are the links for Part 1 and Part 3.)
In the first article of this three part series, we talked about streaming systems, the associated event paradigm inherent in streams and how these concepts are seen at different levels of abstraction, the…
Characteristics, Types & Components of an Event Stream Processing System
(Note that this is Part 1 of a three-part series on Event Stream Processing. Here are the links for Part 2 and Part 3.)
Like many technology-related concepts, Streams or “Event Streaming” is understood in many different contexts and in many different ways such that expectations for Event Stream Processing (ESP) vary…
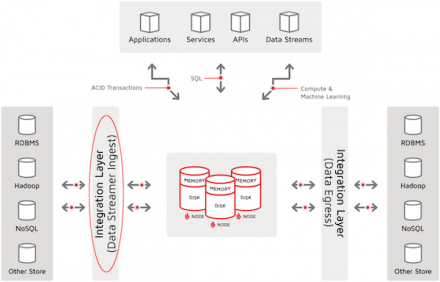
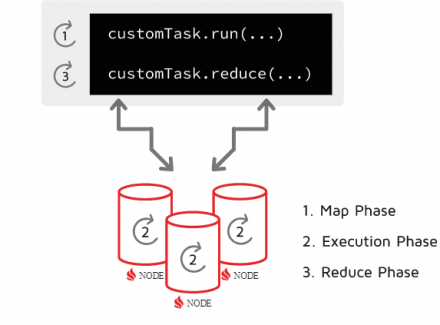
In this third article of the three-part series “Getting Started with Ignite Data Loading,” we continue to review data loading into Ignite tables and caches, but now we focus on using the Ignite Data Streamer facility to load data in large volume and with highest speed.
Apache Ignite Data-Loading Facilities
In the first article of this series, we discussed the facilities that are available to…
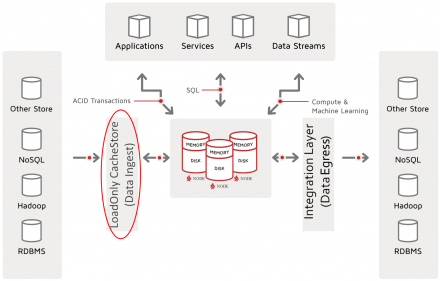
In this second article of the three-part “Getting Started with Ignite Data Loading” series, we continue our review of data loading into Ignite tables and caches. However, we now focus on Ignite CacheStore.
CacheStore Load Facility
Background
Let’s review what was discussed about CacheStore in “Article 1: Loading Facilities.”
The CacheStore interface of Ignite is the primary vehicle used in…
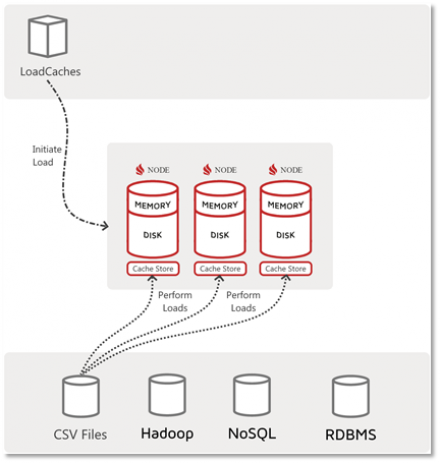
With this first part of “Getting Started with Ignite Data Loading” series we will review facilities available to developers, analysts and administrators for data loading with Apache Ignite. The subsequent two parts will walk through the two core Apache Ignite data loading techniques, the CacheStore and the Ignite Data Streamer.
We are going to review these facilities in relation to specific…

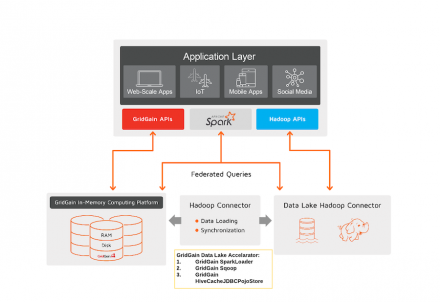
Hadoop Data Lakes are an excellent choice for analytics and reporting at scale. Hadoop scales horizontally and cost-effectively and performs long-running operations spanning big data sets. GridGain, in its turn, enables real-time analytics across operational and historical data silos by offloading Hadoop for those operations that need to be completed in a matter of seconds or milliseconds.
In…
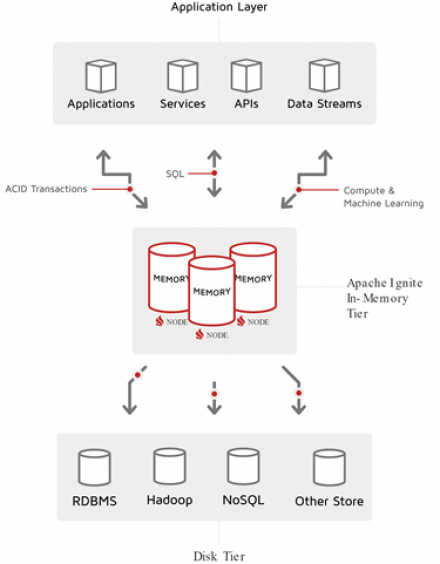
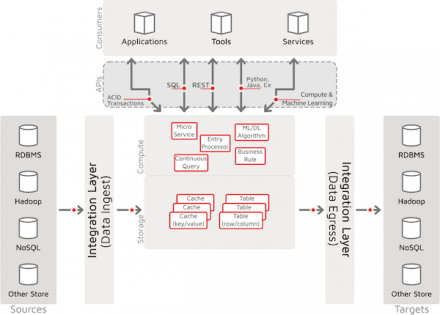
Apache Ignite Deployment Patterns
The Apache Ignite® in-memory computing platform comprises high-performance distributed, multi-tiered storage and computing facilities, plus a comprehensive set of APIs, libraries, and frameworks for consumption and solution delivery (all with a “memory first” paradigm). This rich set of capabilities enables one to configure and deploy Ignite in many diverse…


Note: This is the third and final post in the blog series: Continuous Machine Learning at Scale With Apache Ignite. For post 1 click here and for post 2 click here.
In my first post, I introduced Apache® Ignite™ machine learning and explained how it delivers large-scale, distributed, machine-learning (ML) workloads. In my second post, I discussed the Apache Ignite model-building stages. The…