
Introduction
Apache® Ignite™ provides support for a number of major programming languages. Recently, support for additional programming languages has also been added using what is termed as a Thin Client. New Thin Clients include Python, PHP and Node.js.
The characteristics of a Thin Client are as follows:
It is a lightweight Ignite client that connects to a cluster using a standard socket…
GridGain Blog


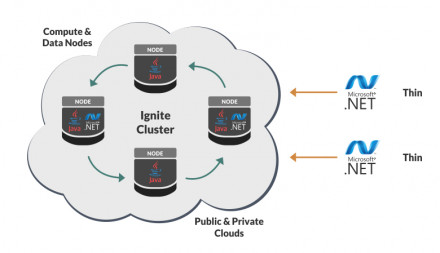
Recently a new version of Apache® Ignite™ was released. Let’s examine some of the new features from the .NET perspective.
Thin .NET Client
Before Apache Ignite version 2.4 (in both Java and .NET), there were two cluster connection modes: Server and Client. Basically, the difference between the client mode and server mode boils down to the following: the client nodes…

Introduction
In the previous article, we discussed the steps required to sign-up for a GridGain® Cloud account, created our first cluster, described the two built-in SQL demos and briefly reviewed the monitoring capabilities. In this article, let's look at examples of how to connect to a GridGain Cloud Cluster using two different programming languages.
Recall that in the previous article, we…


In a previous post, we shared an Apache® Ignite™ primer for people new to this exciting this open source project. In it, we touched upon Ignite's key features. Today I'll focus on the commonly asked question: Does Ignite have persistent storage or memory-only storage?
The answer? Both. Native persistence in Ignite can be turned on and off. This allows Ignite to store data sets bigger than can…

Introduction
In 2018, GridGain® previewed GridGain Cloud. GridGain Cloud enables a GridGain cluster to be run as a service. It supports both distributed in-memory computing and persistence. A number of APIs are supported:
JDBC
ODBC
Binary Protocol and Thin Clients
REST
We will look at examples of some of these APIs in this article series.
GridGain Cloud provides compatibility with…


GridGain's Rob Meyer continues his series on in-memory computing best practices this Thursday when he'll be talking about digital transformation and why delivering a responsive digital business is not possible at scale without in-memory computing.
The webinar is titled, "In-Memory Computing Best Practices: Developing New Apps, Channels and APIs" and I suggest registering now to reserve your…


I’ve created a checklist for new users of Apache® Ignite™ to help overcome common challenges I’ve seen people encounter when developing and configuring their first applications with an Ignite cluster. This checklist was put together from questions new users routinely ask the Apache Ignite community on the user and dev lists. If you are new to Apache Ignite, click here for a quick…
Previously, we looked at how to use GridGain® and Kafka® using a local installation. Let’s now look at an example where we deploy in the Cloud. We will use the GridGain Cloud and the Confluent Cloud environments.
If you'd like to follow along with this example, ensure that you meet the required prerequisites first:
Create an account on the GridGain Cloud
Create an account on the Confluent…

RSVP now for our Dec. 12 webinar and learn how to complement a Relational DBMS for Hybrid Transactional/Analytical Processing (HTAP) by leveraging the massive parallel processing and SQL capabilities of Apache Ignite. Details here.
You'll also learn how to use Apache Ignite as an In-Memory Data Grid that stores data in memory and boosts applications performance by offloading reads from a…

Last week my colleague Valentin Kulichenko, lead architect at GridGain Systems recorded a webinar explaining how companies have been using Apache® Ignite™ to overcome today’s data challenges.
He demonstrated how companies have been using Ignite to add in-memory speed and unlimited horizontal scale to SQL with no rip-and-replace of the underlying database.
The…