
Introduction
AI adoption demands a scalable, high-performance data infrastructure that is able to tap into all relevant data at ultra-low latencies. While offline models use batch data lakes, online AI systems require real-time data access for tasks like feature serving, predictions, and retrieval-augmented generation (RAG). This often leads to complex architectures with multiple data stores.
GridGain for AI simplifies this by unifying feature stores, prediction caches, model repositories, and vector search into one platform. It reduces complexity, lowers costs, and accelerates AI deployment.
Data Store Needs of Online AI
Real-time AI depends on fast retrieval of inputs such as features and embeddings for inference, prediction caching to reduce computation, and dynamic model loading.
Typically, multiple systems – feature stores, caches, and model repositories – are used, adding complexity. GridGain for AI eliminates this by unifying these capabilities into a single, distributed platform. It delivers low-latency performance, seamless scalability, and reduced integration overhead, streamlining deployments and improving overall system efficiency for modern AI applications.
Predictive AI
Predictive AI applications rely on data stores to support critical operations such as managing features, caching predictions, and storing models for inference. GridGain’s architecture addresses these needs by providing a high-speed, scalable platform that ensures real-time predictions and efficient model serving.
Online Predictive AI relies on a few key types of data stores:
- Feature Stores
- Prediction Caches
- Model Stores
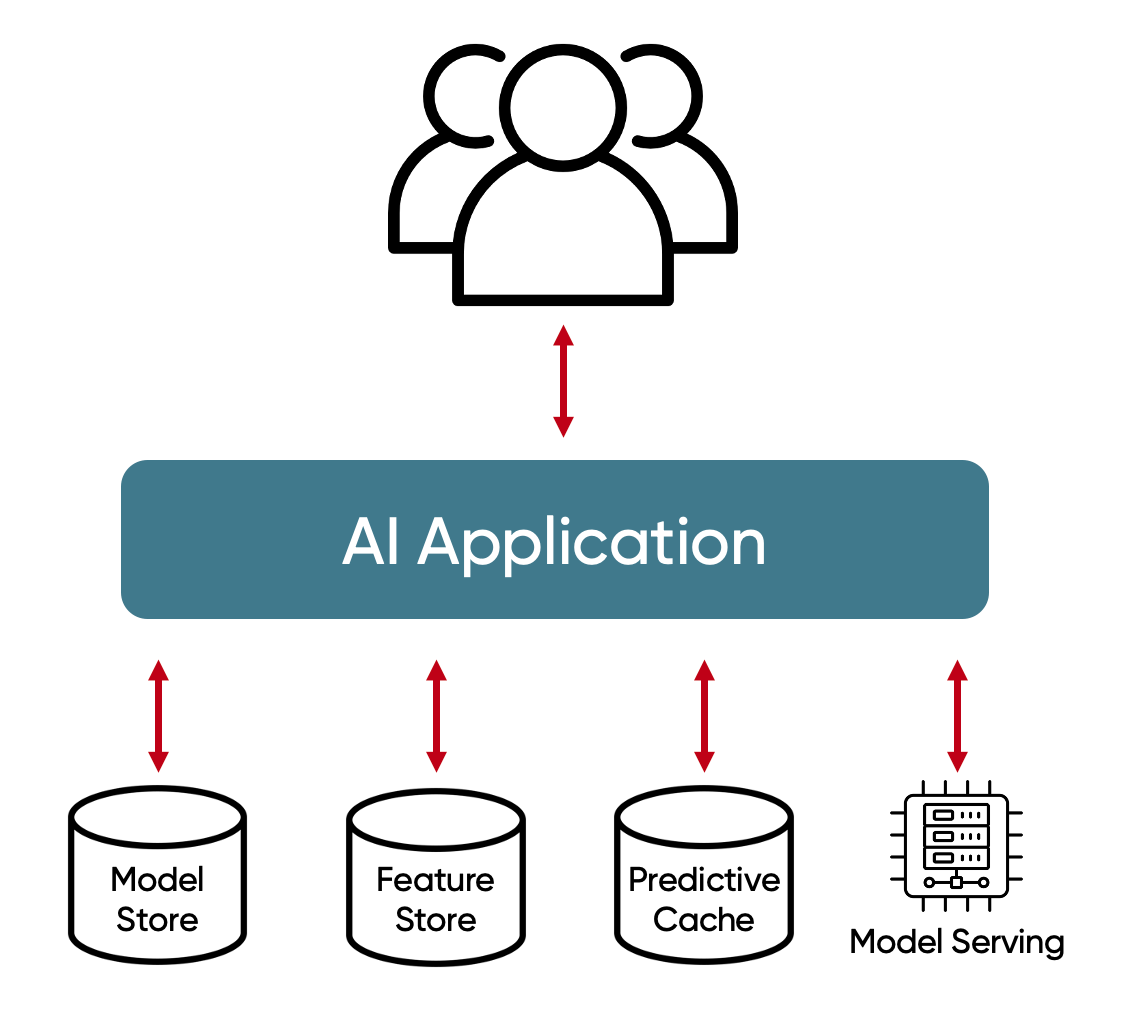
Feature Stores
A Feature Store is a centralized repository for managing model features — the data points that drive predictive models. Online feature stores are crucial for providing real-time access to features during inference, ensuring predictive models can make decisions efficiently.
GridGain as an Online Feature Store:
- GridGain's in-memory speed ensures low-latency access to features for real-time predictions.
- GridGain scales horizontally to handle high-throughput use cases.
- For less latency-sensitive workloads, GridGain provides cost-effective, disk-based storage.
Additionally, GridGain integrates with Feast, a popular open-source feature store, to enable efficient feature management and synchronization.
Prediction Caches
A Prediction Cache stores frequently accessed predictions to reduce model invocation time and associated costs. GridGain is well-suited for prediction caching due to its in-memory distributed storage and ability to scale seamlessly.
Model Stores
A Model Store serves as a repository for versioned machine learning models, offering both storage and fast access for real-time inference. GridGain's low-latency architecture ensures efficient retrieval and application of models.
Generative AI
Generative AI applications, such as Retrieval-Augmented Generation (RAG) applications, require sophisticated data storage for structured and unstructured data. GridGain fulfills these requirements through its support for vector search, full-text search, and SQL-based structured data retrieval.
Generative AI Data Stores
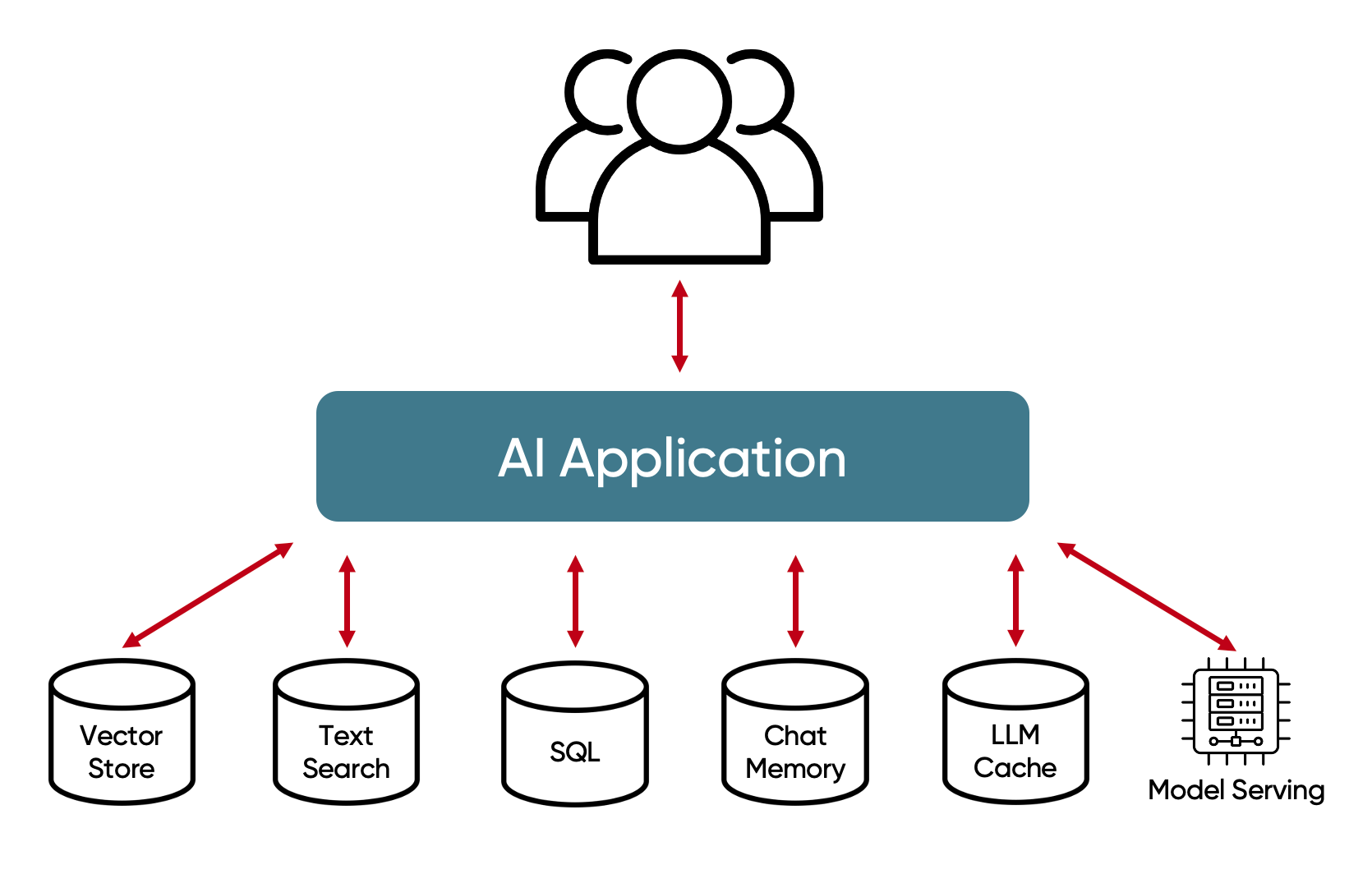
Unstructured Data Retrieval
Unstructured data retrieval is the backbone of RAG systems, enabling AI models to fetch relevant content for augmented responses. GridGain provides distributed vector search for fast similarity lookups and supports full-text search for querying large volumes of unstructured data.
Structured Data Retrieval
Structured data complements unstructured content in RAG workflows. GridGain offers high-performance SQL queries and secondary indexes for efficient structured data retrieval.
Memory / Chat History
Generative AI applications require storage for conversational history to use past interactions as context for future queries. GridGain’s distributed architecture supports scalable storage and retrieval of chat histories.
Caching / Semantic Caching
GridGain provides robust caching capabilities for LLM responses, including semantic caching using vector search to retrieve responses based on query similarity.
Generative AI Integrations
LangChain Integration
GridGain integrates with LangChain as a backend for components like:
- Vector Store for embeddings and similarity search.
- Memory for chat history.
- BaseStore for generic data storage.
- LLM Cache and Semantic LLM Cache for response caching.
- Document Store for content retrieval.
Langflow Integration
Langflow provides a UI-driven approach to building AI pipelines. GridGain is available as a component in Langflow, supporting roles like Vector Store, Chat Memory, and LLM Cache.
Conclusion
AI applications require diverse and often complex data storage infrastructure. From predictive AI’s feature stores and prediction caches to generative AI’s vector search and semantic caching, these systems demand high performance, scalability, and versatility.
GridGain simplifies AI infrastructure by providing a unified data platform with versatile capabilities, including:
- Vector Search: Distributed vector search for embedding-based similarity lookups.
- Full-Text Search: Efficient querying across large text-based datasets.
- SQL-Based Lookups: High-performance SQL queries with indexing.
- Distributed Storage: Memory-centric speed with optional disk persistence.
GridGain integrates seamlessly with key AI tools and frameworks, enhancing its functionality:
- Feast: Integration as an Online Store for real-time feature access.
- LangChain: Backend support for vector search, memory, and caching.
- Langflow: Simplifies production-ready AI pipeline development.
By consolidating these capabilities into a single platform, GridGain simplifies AI deployments, accelerates development, and ensures high performance of AI applications at scale.