

Welcome to part two of our blog series on “Understanding Then Optimizing GridGain Query Processing.” To properly understand this second blog, it’s highly recommended that you familiarize yourself with the background material that was shared in the first blog post of this two-part series.
With the requisite background in place, we can now explore how to overcome the limitations of standard query processing. For a quick review of those limitations, we’ll list them below:
- Standard query processing (SQP) can be impacted by selecting many columns.
- SQP can be impacted by many grouping result rows.
- SQP can be impacted by many hosts sending result rows.
- SQP can be impacted by having a single reducer process executing on one single host.
To overcome these limitations we will have to write some code. As a result, you will likely only use this technique in those instances where you know you are experiencing the aforementioned limitations and need to get the most optimal result times.
Setup
We will use the very same table and query intentions as was outlined in part one of our blog post. For review, here’s the table creation statement:
CREATE TABLE IF NOT EXISTS CAR_SALES (
vin varchar,
sale_date date,
purchase_cost double,
sale_price double,
PRIMARY KEY (vin)
) WITH
"CACHE_NAME=CAR_SALES,
VALUE_TYPE=CAR_SALES";
And here’s the query intention:
SELECT sale_date,
SUM(purchase_cost) AS total_expense,
SUM(sale_price) AS total_income
FROM CAR_SALES
GROUP BY sale_date;
Note that I said “intention,” meaning that we need to produce the same results as the above query but in a more optimal way. So how do we do that? I’ll outline the major steps with snippets of code and direct you to a GitHub that provides the full implementation details at the end of this article.
Step 1
We will need a new temporary table to store interim results. These results will effectively be the same that would normally be produced by the mapper operations. Since this table is transient it will be an in-memory table only, and we won’t use backups for this table. We will, however, use a partitioned table, and we will use affinity for this table by leveraging affinity by date for our interim results.
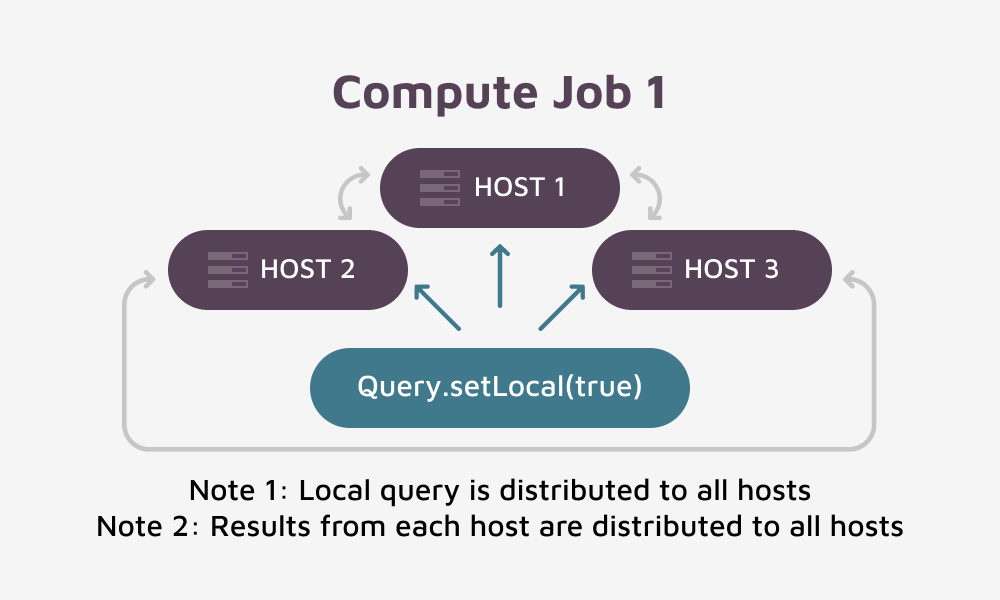
Using affinity by date will locate specific dates on certain hosts rendering two important benefits. Firstly, all dates of the same value (day) will reside on one host. Secondly, all hosts will participate in the collection of the interim result dates, thus removing the limitations of a reducer operation running on one single host. In this instance, since we are using code, we will also get our cache created via code. This provides an example of how to do this via code.
Search for “CarSalesProfitsConfiguration” for details.
Step 2
We now need a compute job that will execute a local query and send the results from that host to our CAR_SALES_PROFITS interim results table. The query implementation will look as follows:
FieldsQueryCursor<List<?>> results = carSalesCache.query(
new SqlFieldsQuery("SELECT sale_date,
SUM(purchase_cost) AS total_expense,
SUM(sale_price) AS total_income
FROM CAR_SALES GROUP BY sale_date;")
.setSchema("PUBLIC")
.setLocal(true));
Take note of the “.setLocal(true)” invocation. This forces the SQL engine to execute the submitted query only against the data that is present on the host the query is executing on.
Next, we will iterate over the results from the local query as in:
Iterator<List<?>> iter = results.iterator();
while(iter.hasNext()) {
…
And for each result we will create an instance of com.gridgain.demo.CarSalesProfits and an instance of com.gridgain.demo.CarSalesProfitsKey to hold and send our results. The CarSaleProfits object will be inserted into the CAR_SALES_PROFITS interim results cache. The complete implementation details can be found in the referenced GitHub project and in the following class: org.gridgain.demo.OptimalQueryMapEmulation
Finally, to get this task executed on all hosts we will bundle the above code into an IgniteRunnable class and have it executed on all hosts via the IgniteCompute.broadcastAsync(IgniteRunnable job) method. We will have to wait until Compute Job 1 completes execution via the returned IgniteFuture<Void> before continuing with Step 3.
These details can be found in the referenced GitHub project and in the following class: com.gridgain.demo.OptimalQueryComputeMain
Step 3
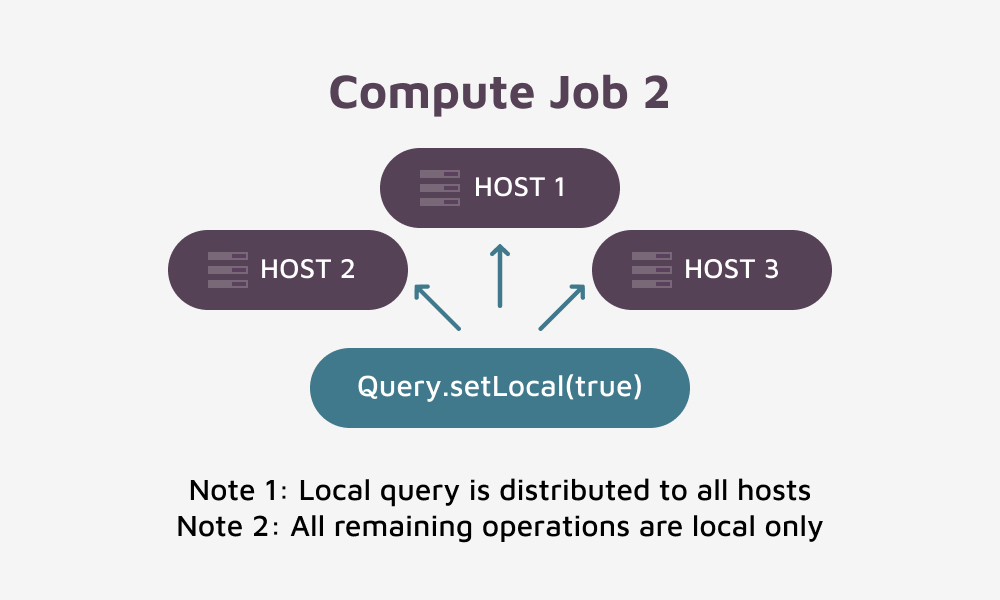
For our final operational step, we will need to consolidate the results for each date. Remember that our interim table used affinity by date – and there were records for all dates on all hosts – but our interim result table uses affinity by date. As a result, each host now holds certain date grouping results, and as such the rows for any specific date will only exist on only one host.
Therefore we can now use a second local query to collect the various data grouping results from each host and roll those into one single row for each date. That is exactly the task for Compute Job 2.
Here’s the query for Compute Job 2:
FieldsQueryCursor<List<?>> results = carSalesProfitsCache.query(
new SqlFieldsQuery("SELECT sale_date,
SUM(total_expense) AS total_expense,
SUM(total_income) AS total_income
FROM CAR_SALES_PROFITS ORDER BY sale_date;")
.setSchema("PUBLIC")
.setLocal(true));
We will iterate through the above results and save one new CarSalesProfits record. After the iteration is complete we will delete all of the existing records from the CarSalesProfits collection and insert our new and final records.
The complete implementation details can be found in the referenced GitHub project and in the following class:
org.gridgain.demo.OptimalQueryReduceEmulation
Getting a Mental Picture of Compute Job 1
Getting a Mental Picture of Compute Job 2
Summary
Through the use of compute jobs, we were able to remove the limitations of a single reducer running on a single host. We were also able to leverage the network interfaces of all hosts by using affinity by date (our grouping clause) and having each host inserted into our interim results table.
Since the interim results table did have affinity by date, grouping records for specific dates were gathered by the system onto the appropriate host for each different date value. This allowed us to follow up Compute Job 1 with Compute Job 2, which was also executed locally and produced the final results for each specific group (date) for our target query!
As a reminder, we suggest that you consider using this technique only in those (hopefully rare) instances where some or all of the following applies:
- You are not able to co-locate your grouping column data using affinity.
- Your target query will produce many grouping results.
- The cluster that you run on has many hosts.
- You need optimal execution times for your query.
If the above variables apply, then the techniques that are shared above will allow you to achieve optimal processing times. Regardless, you should have a solid understanding of how the GridGain SQL operations work and how large selection columns, many groups, and many hosts can impact your SQL query execution times.
Please see the GitHub link below for a project that shares the full implementation details of our compute job for optimal query processing!
Resources:
GitHub Compute Job implementation details:
https://github.com/pnwhitney1/optimal_query_compute
Here’s some background information on Map / Reduce:
https://www.geeksforgeeks.org/mapreduce-architecture/
Here’s a link to GridGain’s SQL Reference Documentation:
https://www.gridgain.com/docs/latest/sql-reference/sql-reference-overview