
Someone one told me that good things come in 3s and, fortunately, that is all it takes to make a well-informed AI-driven decisions in real time as well. The three things we need are:
- Access to all of the relevant data;
- Execution of an intelligent model on that relevant data; and finally
- Doing all of it in real time.
And while it is just these three things and may look to be obvious, as the proverbial “they” say – the devil is in the details. So, lets break down this 3-stage process to execute an AI-based decision and understand these details a little bit more.
Access to Relevant Data
The definition of “relevant” data today has changed. The fact today is that any economical, environmental, or political event anywhere impacts every enterprise across the world. Additionally, technological changes in the last couple of decades, between processing capacities, network speeds, social media and sensors and devices, are leading to more data is being generated every day. As a result, enterprises today have to tap into and process these massive data streams.
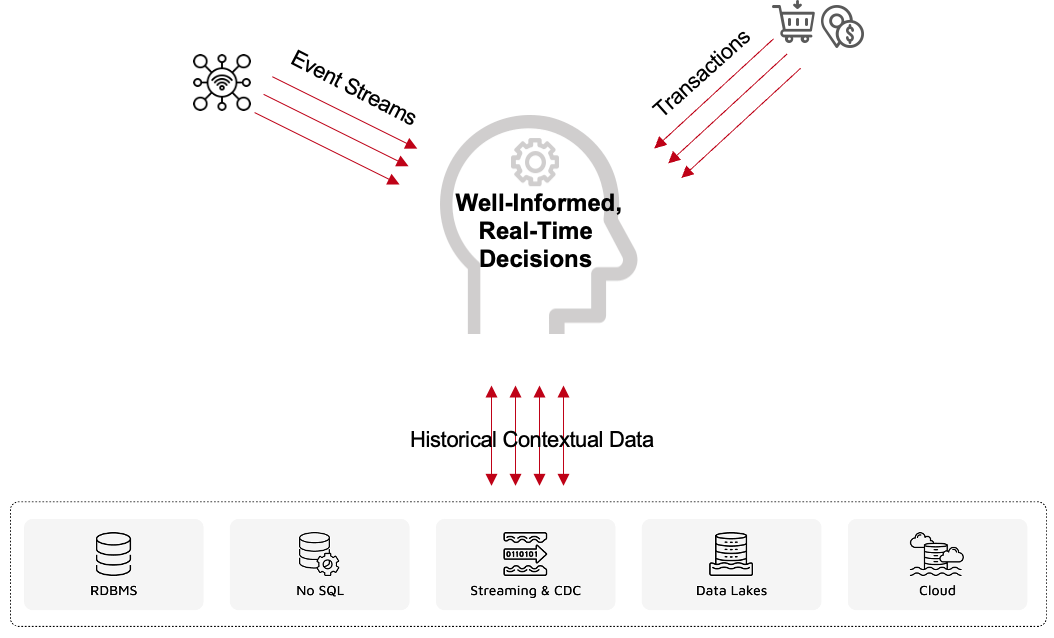 At the same time, just processing transactions or data streams in isolation is not enough, there must be context applied to an event. For example, just looking at a credit card swipe at a gas station in San Francisco is not enough to determine that the transaction is fraudulent unless one also looks at a transaction from two hours earlier that showed the same card being swiped at a deli in New York. This context comes from historical data.
At the same time, just processing transactions or data streams in isolation is not enough, there must be context applied to an event. For example, just looking at a credit card swipe at a gas station in San Francisco is not enough to determine that the transaction is fraudulent unless one also looks at a transaction from two hours earlier that showed the same card being swiped at a deli in New York. This context comes from historical data.
Therefore, the relevant data that needs to be processed and made available to an intelligent model should include:
- Streaming event
- Transactional data
- Historical, contextual data
Execution of an Intelligent Model
Before an AI/ML model can be executed on the relevant data, the data must be prepared appropriately for the model. The streaming event must be embellished with the appropriate context, features have to be extracted or vector embeddings have to be generated. This pre-processed data must be written somewhere for the AI/ML model to access it for processing. Once the model has all the data available to it, it can execute and come up with a well-informed decision.
Real Time Comes with Real Challenges
This is where things start to get complicated. So let us take the conversation one step deeper and further understand these complications.
Historical Data
I casually talked about making historical data available for context. The challenge here is in accessing all the historical data across the enterprise. This data may be sitting in any number of proprietary and customized data stores with data in any number of models and formats. Just knowing what data lies in which store and being able to pull it for context will take time. And if there are many data stores and a large amount of data is needed for context, the problem only magnifies. All sorts of latencies creep in, everything from disk I/O to network latency as data moves over the wire to navigating data model and format differences.
Pre-Processing
Once all the historical data is available, pulling the appropriate data to embellish the streaming event or transactional data itself requires some level of intelligence. Then this data must be embellished or transformed, features have to be extracted, vector embeddings have to be generated, etc. All of this requires reading and writing of data several times before we are ready to execute an AI/ML model.
Model Execution
Before the model can be executed, the execution engine must pull all the relevant data (both the historical context, as well as the newly pre-processed features) from the data store and then execute the model. This also introduces latencies tied to data movement over the network.
Scalability
Across the three activities above, there is always an inherent question around scale. What happens if there is a spike in the event traffic? We see that all the time – Black Friday or Cyber Monday sales in retail, spike in text messages or phone calls in the event of a natural disaster, or a major economic news that leads to massive spikes in trading volumes or financial transactions, etc. So, any unexpected spike in event traffic will strain all the above stages of processing and introduce latencies in the system.
Addressing Inherent Latencies
Each of these challenges mentioned above and the latencies introduced in the system must be addressed to truly enable real-time decision making. Some approaches include:
Digital Integration Hub
A DIH can easily and efficiently consolidate historical data from across 100s of data sources, formats, and models into a low-latency data access layer for your pre-processing engine and the data model. And a distributed, in-memory DIH even minimizes disk I/O, supports horizontal scale and parallel processing for quick retrieval of all sorts of historical data.
Distributed In-Memory Compute Grid
A single distributed compute grid that can pre-process all your data and then execute your AI/ML model, firstly, supports parallel processing of any workloads and, secondly, scales horizontally to keep up with any sudden spikes in workloads.
But we still have the challenge of data movement across application boundaries. As data moves from the DIH to the distributed compute grid, we still have network latency. And this latency is across all stages of the process. Every time we read from the DIH to embellish the streaming event, write features after pre-processing the embellished event or read large data sets for the AI/ML execution, we are introducing network latency into the system.
Real-Time Data Processing Platform for Making AI-Driven Decisions in Real Time
By combining transactions and event processing with a data hub and a compute engine into a single unified platform, one can eliminate or at least minimize the movement of data within the system and thus minimize network latency. And if this platform can be a distributed in-memory platform, it can not only make relevant data available or execute complex AI/ML workloads in a distributed, parallelized fashion, but also do all of this with a time window that renders the decision relevant and useful.
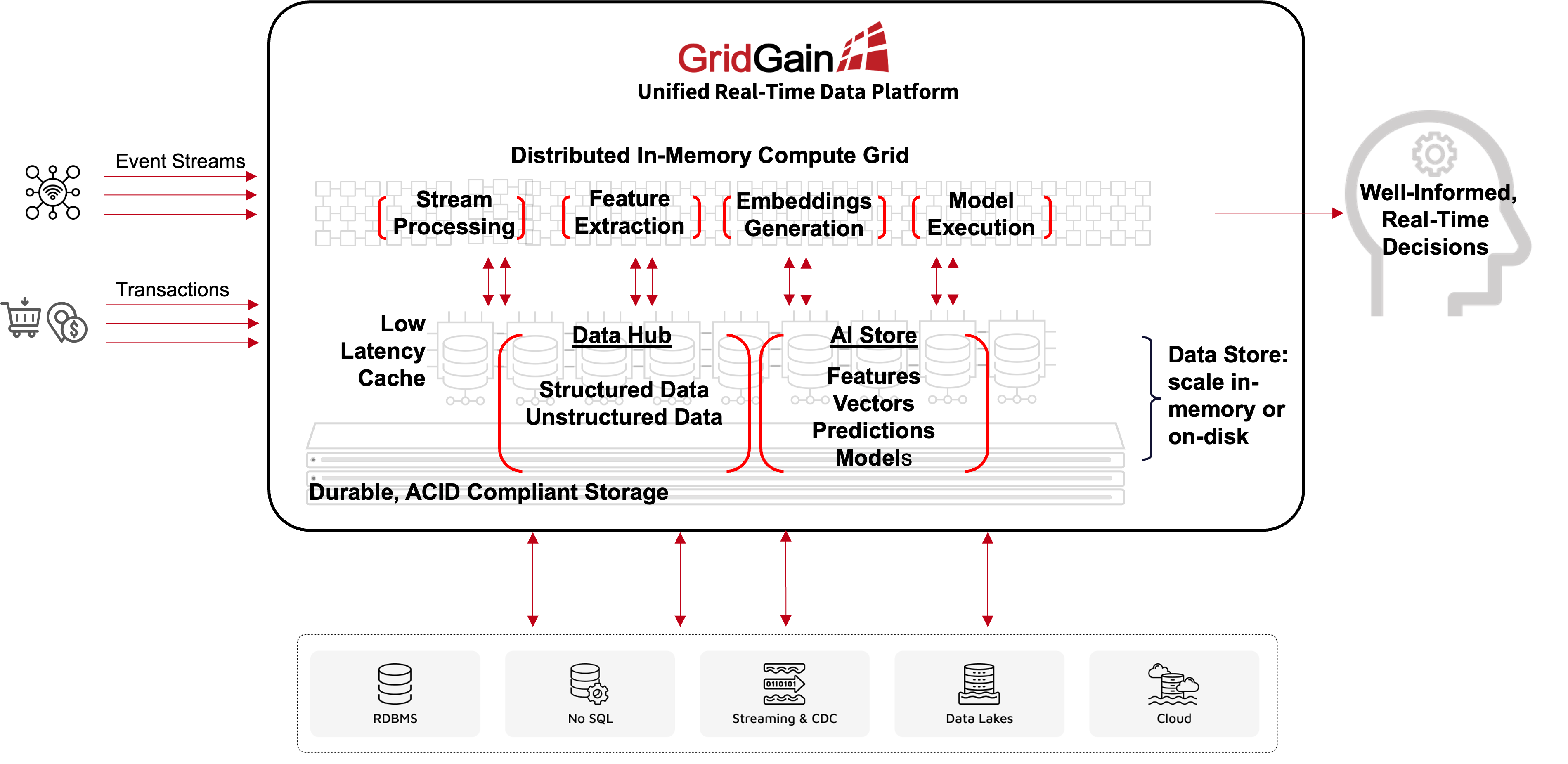
Conclusion
Making an intelligent decision is only useful if it is done in a timely manner and this requires making the relevant data available and the execution of an AI/ML model to be completed at ultra-low latencies. This capability is precisely what a real-time data processing platform offers, in addition to supporting the scale needed to manage unpredictable and increasing workloads. Read this article for a quick primer or download this eBook to learn more about the GridGain Real-Time Data Processing Platform.