
Overview
GridGain is Java-based middleware for in-memory processing of big data in a distributed environment. It is based on high performance in-memory data platform that integrates fast In-Memory MapReduce implementation with In-Memory Data Grid technology delivering easy to use and easy to scale software. Using GridGain you can process terabytes of data, on 1000s of nodes in under a second.
GridGain typically resides between business, analytics, transactional or BI applications and long term data storage such as RDBMS, ERP or Hadoop HDFS, and provides in-memory data platform for high performance, low latency data storage and processing.
Both, GridGain and Hadoop, are designed for parallel processing of distributed data. However, both products serve very different goals and in most cases are very complementary to each other. Hadoop is mostly geared towards batch-oriented offline processing of historical and analytics payloads where latencies and transactions don't really matter, while GridGain is meant for real-time in-memory processing of both transactional and non-transactional live data with very low latencies. To better understand where each product really fits, let us compare some main concepts of each product.
GridGain In-Memory Compute Grid vs Hadoop MapReduce
MapReduce is a programming model developed by Google for processing large data sets of data stored on disks. Hadoop MapReduce is an implementation of such model. The model is based on the fact that data in a single file can be distributed across multiple nodes and hence the processing of those files has to be co-located on the same nodes to avoid moving data around. The processing is based on scanning files record by record in parallel on multiple nodes and then reducing the results in parallel on multiple nodes as well. Because of that, standard disk-based MapReduce is good for problem sets which require analyzing every single record in a file and does not fit for cases when direct access to a certain data record is required. Furthermore, due to offline batch orientation of Hadoop it is not suited for low-latency applications.
GridGain In-Memory Compute Grid (IMCG) on the other hand is geared towards in-memory computations and very low latencies. GridGain IMCG has its own implementation of MapReduce which is designed specifically for real-time in-memory processing use cases and is very different from Hadoop one. Its main goal is to split a task into multiple sub-tasks, load balance those sub-tasks among available cluster nodes, execute them in parallel, then aggregate the results from those sub-tasks and return them to user.
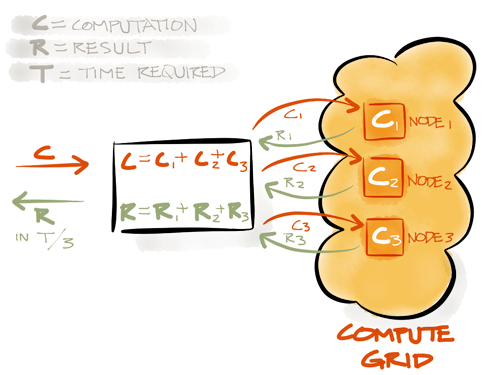
Splitting tasks into multiple sub-tasks and assigning them to nodes is the *mapping* step and aggregating of results is *reducing* step. However, there is no concept of mandatory data built in into this design and it can work in the absence of any data at all which makes it a good fit for both, stateless and state-full computations, like traditional HPC. In cases when data is present, GridGain IMCG will also automatically colocate computations with the nodes where the data is to avoid redundant data movement.
It is also worth mentioning, that unlike Hadoop, GridGain IMCG is very well suited for processing of computations which are very short-lived in nature, e.g. below 100 milliseconds and may not require any mapping or reducing.
Here is a simple Java coding example of GridGain IMCG which counts number of letters in a phrase by splitting it into multiple words, assigning each word to a sub-task for parallel remote execution in the map step, and then adding all lengths receives from remote jobs in reduce step.
[source lang="java"]
int letterCount = g.reduce(
BALANCE,
// Mapper
new GridClosure<String, Integer>() {
@Override public Integer apply(String s) {
return s.length();
}
},
Arrays.asList("GridGain Letter Count".split(" ")),
// Reducer
F.sumIntReducer()
));
[/source]
GridGain In-Memory Data Grid vs Hadoop Distributed File System
Hadoop Distributed File System (HDFS) is designed for storing large amounts of data in files on disk. Just like any file system, the data is mostly stored in textual or binary formats. To find a single record inside an HDFS file requires a file scan. Also, being distributed in nature, to update a single record within a file in HDFS requires copying of a whole file (file in HDFS can only be appended). This makes HDFS well-suited for cases when data is appended at the end of a file, but not well suited for cases when data needs to be located and/or updated in the middle of a file. With indexing technologies, like HBase or Impala, data access becomes somewhat easier because keys can be indexed, but not being able to index into values (secondary indexes) only allow for primitive query execution.
GridGain In-Memory Data Grid (IMDG) on the other hand is an in-memory key-value data store. The roots of IMDGs came from distributed caching, however GridGain IMDG also adds transactions, data partitioning, and SQL querying to cached data. The main difference with HDFS (or Hadoop ecosystem overall) is the ability to transact and update any data directly in real time. This makes GridGain IMDG well suited for working on operational data sets, the data sets that are currently being updated and queried, while HDFS is suited for working on historical data which is constant and will never change.
Unlike a file system, GridGain IMDG works with user domain model by directly caching user application objects. Objects are accessed and updated by key which allows IMDG to work with volatile data which requires direct key-based access.
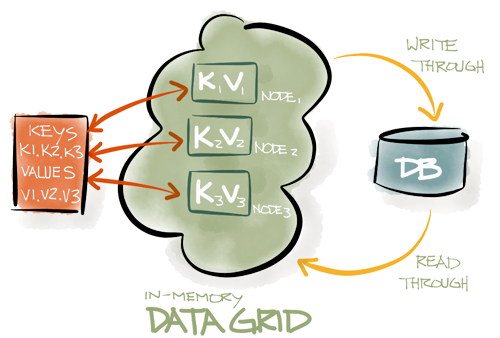
GridGain IMDG allows for indexing into keys and values (i.e. primary and secondary indices) and supports native SQL for data querying & processing. One of unique features of GridGain IMDG is support for distributed joins which allow to execute complex SQL queries on the data in-memory without limitations.
GridGain and Hadoop Working Together
To summarize:
Hadoop essentially is a Big Data warehouse which is good for batch processing of historic data that never changes, while GridGain, on the other hand, is an In-Memory Data Platform which works with your current operational data set in transactional fashion with very low latencies. Focusing on very different use cases make GridGain and Hadoop very complementary with each other.
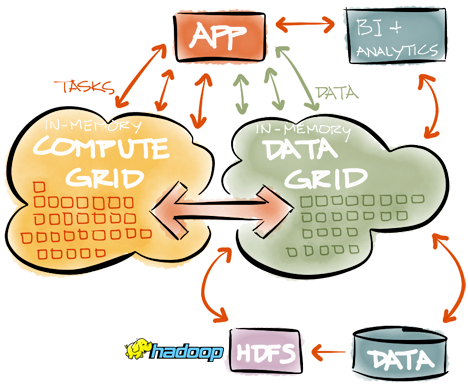
Up-Stream Integration
The diagram above shows integration between GridGain and Hadoop. Here we have GridGain In-Memory Compute Grid and Data Grid working directly in real-time with user application by partitioning and caching data within data grid, and executing in-memory computations and SQL queries on it. Every so often, when data becomes historic, it is snapshotted into HDFS where it can be analyzed using Hadoop MapReduce and analytical tools from Hadoop eco-system.
Down-Stream Integration
Another possible way to integrate would be for cases when data is already stored in HDFS but needs to be loaded into IMDG for faster in-memory processing. For cases like that GridGain provides fast loading mechanisms from HDFS into GridGain IMDG where it can be further analyzed using GridGain in-memory Map Reduce and indexed SQL queries.
Conclusion
Integration between an in-memory data platform like GridGain and disk based data platform like Hadoop allows businesses to get valuable insights into the whole data set at once, including volatile operational data set cached in memory, as well as historic data set stored in Hadoop. This essentially eliminates any gaps in processing time caused by Extract-Transfer-Load (ETL) process of copying data from operational system of records, like standard databases, into historic data warehouses like Hadoop. Now data can be analyzed and processed at any point of its lifecycle, from the moment when it gets into the system up until it gets put away into a warehouse.