
Read Consistency - Strong Consistency vs Eventual Consistency and How to Configure Them in GridGain and Apache Ignite
In single-host data storage and processing software, data that is successfully written to data storage can be immediately read by clients. If two readers query at the same time, they’ll get the same values. This is referred to as strong consistency. Many high-scale distributed databases, data grids, data lakes, etc. have the opposite–eventual consistency.
Eventual consistency is fine for some use cases. For example, imagine you were doing research on a topic, say “Causal Inference” in data science, and you searched a database with all academic papers on that subject at the same time someone else on the other side of the country searched for the same thing. If you got all the papers on the subject, except one that had just been entered into the system, and the other person got all the papers including that one, it would make little difference. There would be no great consequences if your query result was not exactly the same as theirs. In this use case, eventual consistency is acceptable.
On the other hand, if two people on opposite sides of the country both query your bank balance, they better get the same answer or there could be serious consequences. Strong read consistency at scale is important for most use cases, but it’s especially important in transactional workloads such as those in financial services.
There are multiple cache configurations that can influence read consistency in GridGain and Apache Ignite. In GridGain version 8.x and Apache Ignite version 2.x, you can configure your caches for optimal read performance. You can also configure your caches for optimal write performance. Either way, you want to ensure that you also evaluate read consistency requirements for each data cache. Different caches can have different read consistency needs.
This article will review the basics of distributed data in a GridGain cluster. With that as background, you will learn how read consistency can be impacted by various cache configurations. These configurations can impact both read and write performance. After learning how GridGain 8 and Apache Ignite 2 handle this, you will learn a bit about how GridGain 9 and Apache Ignite 3 address read consistency differently.
How GridGain 8 & Apache Ignite 2 Distribute Data
Before we address configuration options, it is important to understand typical data distribution for a GridGain 8.x / Ignite 2.x cluster. A cluster typically consists of many hosts. By default, a cache has 1024 partitions. You can think of a partition as a division of your overall data set where each partition contains approximately one 1024th of your overall data set. These 1024 partitions are distributed as evenly as possible across your hosts.
Most partitioned caches are configured for at least 1 backup. With one backup there will also be 1024 backup partitions. The system will guarantee that backup partitions will always be on a different host than your primary partitions. This supports system stability in the event of a host failure.
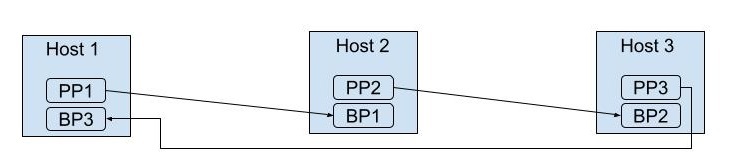
Listed below is a graphic showing multiple hosts, each with just one primary partition (PPx) and one backup partition (BPx). For a real cluster, each host would have many primary and backup partitions, not just one on each host.
Write Performance Configuration Options
One cache configuration property that impacts write performance is referred to as “writeSynchronizationMode”. Write Synchronization Mode has three possible settings. These are FULL_ASYNC, PRIMARY_SYNC and FULL_SYNC.
- FULL_ASYNC mode: Writing clients do not wait for responses from the participating hosts. You can think of this as fire and forget. This is the fastest, but least reliable mode.
- PRIMARY_SYNC mode: Writing clients will wait for the write to complete on the primary partition. This is the second fastest mode and is highly reliable.
- FULL_SYNC mode: Writing clients will wait for the write to complete on both the primary partition and all backup partitions. This is the slowest mode, but is often used for heavy read use cases.
Read Performance Configuration Options
One cache configuration property that impacts read performance is referred to as “readFromBackup”. Read from backup can be set to true or false.
readFromBackup=true: If a read operation is initiated from a host that has the target backup partition, then the client is allowed to read the data from the backup partition. This saves the client from forcing the read to be made from the host that has the primary partition. This can improve read performance!readFromBackup=false: The client must read all data from the primary partition even if the primary partition is on another host. This can negatively impact read performance due to the reading client being forced to accomplish the reading operation from the host that holds the primary partition. But this can be a wise choice if you are optimizing for heavy write use cases.
Stale Reads
Based on that information, if you want a cluster to operate at maximum performance for both read and write operations with reasonable reliability, you might set writeSynchronizationMode=PRIMARY_SYNC and readFromBackup=true.
The above settings will provide for good read & write performance. But what about read consistency? A client might write into a cache on the host that has the primary partition, but simultaneously, another client might attempt to read the data from a host that has the same record in a backup partition. The write operation may not yet have been synchronized to the backup partition, so the reading client would get a prior version of data. This is referred to as a stale read.
The graphic below shows this stale read example:

For some use cases, this might be perfectly acceptable, but certainly not if you are executing financial transactions. For mission critical use cases, be sure to evaluate all affected caches for their read consistency configuration requirements.
Configuring for Strong Read Consistency
There are two ways to configure for strong read consistency. Which way you configure depends on if your caches are used for use cases that have heavy writing demands but fewer read demands. The other way is to configure for use cases that have heavy read demands but fewer write demands. We will touch briefly on balanced workload configurations as well.
Optimize Reading Performance for Read-Heavy Workloads
For caches that get read much more than written to, consider optimizing for reads by setting readFromBackup=true. But to be sure you have strong read consistency you will pay a small performance penalty on your write operations by setting writeSynchronizationMode=FULL_SYNC.
The graphic below shows strong read consistency for read-heavy workloads:

Note that the reading user will see the latest value from the backup partition as soon as that insert operation has completed successfully.
Optimize Writing Performance for Write-Heavy Workloads
For caches that get written to much more than read from, consider optimizing for writes by setting writeSynchronizationMode=PRIMARY_SYNC. But to ensure you have strong read consistency, you will pay a small performance penalty on your read operations by setting readFromBackup=false.
The graphic below shows strong read consistency for write-heavy workloads:

Regardless of when the update is made to the backup partition, the reading client is forced to read the data from the primary partition. This forces an additional network hop to retrieve the requisite data.
Balanced Workloads & Transactions
For balanced workloads, you could configure for either optimized reading or optimized writing. It would very likely be worth the time and effort to gather some read and write counts for caches that are used on your cluster to help make that determination. Given a choice between the two, generally, optimized reading would be the wisest choice, but that is only suggested based on the notion that most use cases are written once and read many times (WORM). For any use of transactions where you are asking the system to ensure that your write operations either complete or fail en masse, then you will surely want to ensure that you are configured for strong read consistency.
Read Consistency in GridGain 9 & Apache Ignite 3
There are multiple good news elements that are related to the latest versions of GridGain Platform and Apache Ignite. By default all transactions in these latest versions are strictly serializable. In both, a transaction is started even if you do not explicitly create one. These latest releases improve on the performance of transaction-based activities in large part due to their use of Multi Version Concurrent Control (MVCC). And lastly, GridGain 9 and Apache Ignite 3 implement strong read consistency by default for all tables and all caches. So you get higher performance, strong read consistency, and simpler table configuration. That’s a win, win, win every day!
Summary
In GridGain 8 & Apache Ignite 2, there are many cache configuration options to consider for read and write performance. Ensuring strong read consistency is critically important for many use cases. If you are using transactions in particular, then please verify that you have configured your caches for strong consistency. For GridGain 9 & Apache Ignite 3, there is less to consider due to the core architecture of these versions having been designed to support strong read consistency by default. So, now you can confidently say you know how to read that write right!
Additional Read Consistency Information
Blog post on Latest Features in Ignite 3:
https://www.gridgain.com/resources/blog/whats-new-in-apache-ignite-3-0
Learn more at GridGain University:
https://university.gridgain.com/
About GridGain 9
https://www.gridgain.com/products/gridgain-9
GridGain 8 cache configuration documentation:
https://www.gridgain.com/docs/latest/developers-guide/configuring-cache…
GridGain 8 backup configuration documentation:
https://www.gridgain.com/docs/latest/developers-guide/configuring-cache…
Apache Ignite 2 cache configuration documentation:
https://ignite.apache.org/docs/latest/configuring-caches/configuration-…
Apache Ignite 2 backup configuration documentation:
https://ignite.apache.org/docs/latest/configuring-caches/configuring-ba…